
The Donald Cloud
Yesterday, I came across this interesting cloud on Kaggle that was created around the silhouette of Hillary Clinton and was based on the database of her emails. Although not a fan of Trump, I decided to utilise the database of the Tweets from the first GOP debate and create a word cloud in the shape of a silhouette of the Donald’s picture.
However, there were a few caveats that I ran into. For one, my script is based in R, whereas all of my online search led me only to scripts and libraries in Python for creating a word cloud in the shape of a specific image. Thus, although I have been able to create a wordcloud of tweets during the debate that mentioned Trump and was able to colour-code them according to the sentiment of the tweets, my dream of creating a beautiful (almost as beautiful as his famed border-dividing wall is supposed to be), racist, hate-filled silhouette of that famous(or fake?) orange hair and smug face surrounded by a wordcloud of racist, vile tweets is partly on hold. For the moment, I have to make peace with a big, ugly blob of tweets mentioning Trump. Nevertheless, here is the code for this wordcloud, along with a description of the code.
Load the following libraries in R:
library(ggplot2)
library(readr)
library("tm")
library("SnowballC")
library("wordcloud")
library("RColorBrewer")
Load the data from a csv file, and carry out some formatting to the tweets.
tweets <- read.csv("../input/Sentiment.csv")
tweets$text <- gsub("#GOPDebate", "", tweets$text)
tweets$text = gsub("(RT|via)((?:\\b\\W*@\\w+)+)", "", tweets$text)
tweets$text <- gsub("#GOPdebate", "", tweets$text)
tweets$text = gsub("[[:punct:]]", "", tweets$text)
tweets$text = gsub("[[:digit:]]", "",tweets$text)
tweets$text = gsub("http\\w+", "", tweets$text)
tweets$text = gsub("[ \t]{2,}", "", tweets$text)
tweets$text = gsub("^\\s+|\\s+$", "", tweets$text)
tweets$text = gsub("amp", "", tweets$text)
tweets$text = gsub("[^\x20-\x7E]", "", tweets$text)
Create a data frame that contains the text, sentiment count and number of retweets of every tweet.
tweet_data <- subset(tweets,selec=c("text","sentiment","retweet_count"))
Then, create factor levels for the sentiments and run the following functions.
sents = levels(factor(tweet_data$sentiment))
labels <- lapply(sents, function(x) paste(x,format(round((length((tweet_data[tweet_data$sentiment ==x,])$text)/length(tweet_data$sentiment)*100),2),nsmall=2),"%"))
nemo = length(sents)
emo.docs = rep("", nemo)
for (i in 1:nemo)
{
tmp = tweet_data[tweet_data$sentiment == sents[i],]$text
emo.docs[i] = paste(tmp,collapse=" ")
}
Remove specific stopwords in German and English from the tweets.
emo.docs = removeWords(emo.docs, stopwords("german"))
emo.docs = removeWords(emo.docs, stopwords("english"))
Create the corpus of tweets and create a term document matrix to generate the word cloud
corpus = Corpus(VectorSource(emo.docs))
tdm = TermDocumentMatrix(corpus)
tdm = as.matrix(tdm)
colnames(tdm) = labels
Finally, generate the word cloud that displays the tweets arranged in the order of their retweets and divided according to their sentiment.
comparison.cloud(tdm, colors = brewer.pal(nemo, "Dark2"),
scale = c(3,.5), random.order = FALSE, title.size = 1.5)
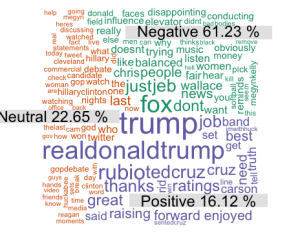
There, a blob of tweets for a blob of a candidate.
Next assignment: generate a much cooler portrait wordcloud that takes the fight to the 1 percent #feelthebern.
This post was originally published on Medium
Leave a Comment